The Null Device
Posts matching tags 'data mining'
2015/3/1
We Can Marry You Off Wholesale, a hypothetical piece set in an alternate universe where Facebook is evil and uses its power to monitor and manipulate human relationships to keep its users optimally unhappy for profits:
Facebook knew you were in love a long time before you did. It noticed you scrolling back through her timeline. Every millisecond lingering over the photos of her at the beach was faithfully logged.
On the surface, you two were perfectly suited to each other. But Facebook had detected a problem. At your age, it's hard for Facebook to make money from your love. Sure, a promotion for flowers earns a few bucks. Adverts for romantic dinners can bring in some cash. But here's not much money in that.
So Facebook acted. It "lost" the occasional message you sent her. It made sure that photos of her with other guys were always at the top of your newsfeed. She mostly saw your posts about drinking - and all the girls who had liked your status updates.
With perfect algorithmic efficiency, Facebook found you a beautiful wife who was practically guaranteed to produce a sickly child. Nothing too bad, mind you, but just ill enough to make you spend a little bit more than you would otherwise. A child is a joyous event. Lots of photos posted to Facebook. Lots of likes. Lots of inspiring updates about bravely struggling.This is, as the author points out, a work of fiction, though once the deep-learning algorithms are given access to all incoming data and control of the entire system, and optimised only to solve one problem (maximise profits, whilst avoiding a list of forbidden tactics that someone has thought of), there may be millions of subtly malevolent scams like this, all of them too complex for any human in a position of oversight to understand. Billions of equations, predicated on complicated models of circumstances and human behaviours, combining into scenarios which result in one or more users becoming slightly better-performing profit centres.
2013/6/7
Recently leaked slides from a NSA PowerPoint presentation have revealed that US internet companies, including Google, Facebook, Microsoft and Apple have been giving the NSA access to their users' private data since 2007. The data in question includes emails, instant messages, video and voice chat, stored data, online social networking details and “special requests”. The programme for harvesting this data is known internally as PRISM. This revelation comes a day after revelations that the NSA is indiscriminately collecting phone records of US mobile phone company customers, including their locations and whom they have been calling/texting and when.
The companies implicated in the slide deck have issued carefully-worded denials, claiming that they have never heard of anything called PRISM (likely, as that was probably an internal NSA codename not revealed to the outside world), have never provided the NSA with direct access to their servers (which could just mean that the NSA had to request items of data, or sets of items of data, and got an itemised bill for them).
Of course, this would mean that the NSA has had the task of wading through vast amounts of trivia: of social chatter, chain letters, forwarded amusing cat/sloth/lemur photos (which they'd have to check for steganographed terrorist plans, of course), mundane updates about people's lunch choices/music listening/reaction to last night's Game Of Thrones episode, online shopping receipts, steamy texts to lovers, drunkfaced party photos, viral ads, skinnerbox game invitations, complaints about traffic/public transport/coworkers and such. Though one wonders to what extent this can be automated. For decades, the US intelligence community has been investing millions in artificial intelligence research (a holy grail of CIA-funded research a while ago was the problem of “gisting”, or accurately summarising large amounts of text for human consumption; this is a hard problem, because it requires semantic knowledge about what the text is about). Meanwhile, in the private sector, data mining has shown uncannily accurate results, to the point where retailers have to insert a few deliberately inaccurate or useless coupons into the books they send to customers as not to freak them out with how much they know their true heart. (Remember the story about the angry father demanding why Target was sending his teenage daughter coupons for nappies and prams, and then apologising a few weeks later when she confessed that she was actually pregnant?)
If the NSA has had an firehose-like feed of personal information on millions of individuals for years, it's not unreasonable to expect that some proportion of the multi-trillion-dollar US “black budget” has been allocated to research into finding ways of aggregating, interpreting and processing this information to build up summaries or models of individuals. These could be automated dossiers with estimated personality profiles (“probabilities of paranoia: 23% issues with authority: 17%, narcissism: 27%, procrastination: 53%, adherence to routine: 61%. Most likely to fear: abandonment (41%), cancer (37%), rats (29%), exposure of peccadillos (23%). Probably responsive to: intimidation (43%), flattery (37%)”), which could be useful if the powers that be need to apply subtle, very precise pressure on a conveniently located bystander to use them against someone like al-Qaeda or Occupy. If they have real-time information, such as the mobile phone metadata (and, even omitting the content of conversations, having a record of the location of a person's phone can reveal a lot about what they're doing), they could even get alerts when somebody deviates from their routine more than they typically do; a dive into their private data would reveal whether they're planning a surprise anniversary party for their spouse or a terrorist attack. (Spoiler: it's almost never a terrorist attack.)
Of course, what the social and psychological effects of such surveillance are is another question. If there is a class of watchers, who can peer into the deepest secrets of the rest of the population, would their attitude to the pitiful, flawed wretches before them, with their pathetic little sins and failings, not be one of contempt? Would they not start regarding the rest of the population as little more than cattle, much as the participants in the Stanford Prison Experiment did?
2012/10/1
An article in the Guardian presents a scenario on the privacy risks even the most careful social media output could pose when analysed with data-mining software descended from that currently in existence:
"Tina Porter, 26. She's what you need for the transpacific trade issues you just mentioned, Alan. Her dissertation speaks for itself, she even learned Korean..." He pauses.Of course, if employers (and health insurance companies and the police and organised criminals and advertising firms and psychotic stalkers) can data-mine a tendency to get migraines from the fluctuation of the vocabulary of one's posts, one might suggest that those with a healthy amount of paranoia should avoid social media altogether, beyond having a simple static page that gives away absolutely nothing. Except that not having an active social media profile is increasingly seen as suspicious in itself; if you're not tweeting your TV viewing or Instagramming your sandwiches and leaving a statistically normal trail of well-adjusted narcissistic exhibitionism, there's a nonzero probability that you might be the next Unabomber; and, in any case, the HR department who knocked Tina Porter back for her carefully concealed migraines would certainly not even look at the CV of the potential ticking timebomb whose online profile draws a blank.
"But?..." Asks the HR guy.
"She's afflicted with acute migraine. It occurs at least a couple of times a month. She's good at concealing it, but our data shows it could be a problem," Chen says.
"How the hell do you know that?"
"Well, she falls into this particular Health Cluster. In her Facebook babbling, she sometimes refers to a spike in her olfactory sensitivity – a known precursor to a migraine crisis. In addition, each time, for a period of several days, we see a slight drop in the number of words she uses in her posts, her vocabulary shrinks a bit, and her tweets, usually sharp, become less frequent and more nebulous. That's an obvious pattern for people suffering from serious migraine. In addition, the Zeo Sleeping Manager website and the stress management site HeartMath – both now connected with Facebook – suggest she suffers from insomnia. In other words, Alan, we think you can't take Ms Porter in the firm. Our Predictive Workforce Expenditure Model shows that she will cost you at least 15% more in lost productivity."
So, if this sort of thing comes to pass (and whether that sort of data could be extracted from social data with few enough false positives to be useful is a big if), we may eventually see an age of radical transparency, where everyone knows who's likely to be marginally more or less productive, along with possible laws regulating when this may be taken into account. Either that or the evolution of Gattaca-style systems and techniques for chaffing one's social data trail and masking any deficiencies which it may betray, in an ever-escalating arms race with new analytical techniques designed to detect such gaming.
2012/2/18
The New York Times has a fascinating article about how retail companies use data mining and carefully targeted coupons to analyse and influence the spending habits of consumers, without the consumers getting wise to what's happening and resisting:
Almost every major retailer, from grocery chains to investment banks to the U.S. Postal Service, has a “predictive analytics” department devoted to understanding not just consumers’ shopping habits but also their personal habits, so as to more efficiently market to them. “But Target has always been one of the smartest at this,” says Eric Siegel, a consultant and the chairman of a conference called Predictive Analytics World. “We’re living through a golden age of behavioral research. It’s amazing how much we can figure out about how people think now.”A specific case the article describes is that of finding new parents-to-be, who will soon be in a position of having to form new spending habits, and doing so before the competition can identify them from public information; which is to say, inferring from statistical information whether a customer is likely to be pregnant, and at which stage, and then subtly manipulating her spending through the various milestones of her child's development:
The only problem is that identifying pregnant customers is harder than it sounds. Target has a baby-shower registry, and Pole started there, observing how shopping habits changed as a woman approached her due date, which women on the registry had willingly disclosed. He ran test after test, analyzing the data, and before long some useful patterns emerged. Lotions, for example. Lots of people buy lotion, but one of Pole’s colleagues noticed that women on the baby registry were buying larger quantities of unscented lotion around the beginning of their second trimester. Another analyst noted that sometime in the first 20 weeks, pregnant women loaded up on supplements like calcium, magnesium and zinc. Many shoppers purchase soap and cotton balls, but when someone suddenly starts buying lots of scent-free soap and extra-big bags of cotton balls, in addition to hand sanitizers and washcloths, it signals they could be getting close to their delivery date.
One Target employee I spoke to provided a hypothetical example. Take a fictional Target shopper named Jenny Ward, who is 23, lives in Atlanta and in March bought cocoa-butter lotion, a purse large enough to double as a diaper bag, zinc and magnesium supplements and a bright blue rug. There’s, say, an 87 percent chance that she’s pregnant and that her delivery date is sometime in late August. What’s more, because of the data attached to her Guest ID number, Target knows how to trigger Jenny’s habits. They know that if she receives a coupon via e-mail, it will most likely cue her to buy online. They know that if she receives an ad in the mail on Friday, she frequently uses it on a weekend trip to the store. And they know that if they reward her with a printed receipt that entitles her to a free cup of Starbucks coffee, she’ll use it when she comes back again.The uncanny accuracy of the algorithm is demonstrated by an anecdote about an angry father storming into a Target store demanding why they had sent his teenaged daughter coupons for nappies and prams, and then, some time later, returning to apologise, having discovered that she had, in fact, become pregnant.
Of course, there is the small issue of how to use this wealth of information in a plausibly deniable sense, without being obviously creepy. People, after all, tend to react badly to being surreptitiously watched and manipulated, especially so when deeply personal matters are involved:
“With the pregnancy products, though, we learned that some women react badly,” the executive said. “Then we started mixing in all these ads for things we knew pregnant women would never buy, so the baby ads looked random. We’d put an ad for a lawn mower next to diapers. We’d put a coupon for wineglasses next to infant clothes. That way, it looked like all the products were chosen by chance. And we found out that as long as a pregnant woman thinks she hasn’t been spied on, she’ll use the coupons. She just assumes that everyone else on her block got the same mailer for diapers and cribs. As long as we don’t spook her, it works.”
2012/2/5
Data wonks at the social music-streaming site last.fm have been taking advantage of their vast repository of recorded music to correlate analyses of the music (made using cold, hard signal-processing algorithms, not anything more subjective or fuzzy) with data from sales charts, determining how the characteristics of popular music have changed in response to cultural trends. The results make for fascinating reading.
Among findings: by looking at how percussive tracks in the charts were (i.e., how strong and regular a rhythm they had, according to spectral analyses) they pretty much pinpoint the rise of disco in the mid-1970s, a change towards more strongly rhythmic tracks which has never been reversed:
The rise in percussivity was followed by a rise in rhythmic regularity in the early 1980s, when drum machines and MIDI came into existence. Unlike the increase in percussivity, though, this was a temporary hump, which waned in the 1990s, as people got sick of drum machines, grunge/alternative did to overproduced 1980s studio-pop what punk had done to prog, and/or simple 16-step drum machines were replaced by Atari STs running Steinberg Cubase, and equipped with more humanlike quantisation algorithms. Interestingly enough, the same study found that the hump in rhythmic regularity was accompanied by a rise in tracks with a tempo of 120 beats per minute, either out of laziness or from some folk wisdom about 120bpm being the optimum tempo: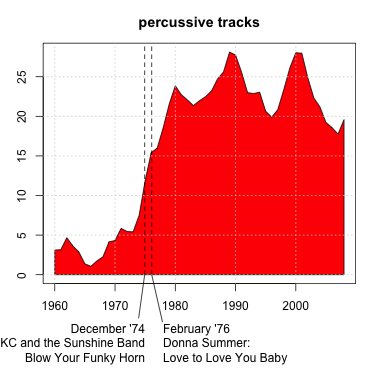
Our first thought was that songwriters in the 80s must have turned on their drum machines, loved what they heard and wrote a song to that beat - without changing the default tempo setting of 120 bpm. I would love this to be correct, but I have a hunch that it's not, especially after having found this highly interesting manual for writing a hit single written by The KLF in 1988. They say that "the different styles in modern club records are usually clustered around certain BPM’s: 120 is the classic BPM for House music and its various variants, although it is beginning to creep up", and also, "no song with a BPM over 135 will ever have a chance of getting to Number One" because "the vast majority of regular club goers will not be able to dance to it and still look cool".Time, as the KLF said, may be eternal, but time signatures aren't; dance music (which remained strongly clustered around 120bpm at the time of acid house and the Second Summer of Love) soon started creeping upward past 130bpm, while tempos of charting music in general moved down.
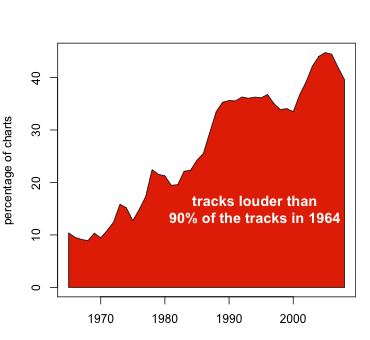
last.fm's DSP algorithms also pick out the rise of punk, with its simplistic rock'n'roll arrangements and emphasis on DIY enthusiasm over polished virtuosity, and the vanquishment of prog rock, glam and other more experimental genres; this manifested itself in a steep rise in the proportion of the charts occupied by records of low harmonic and timbre complexity (i.e., both simple melodic/chord structures and unostentatious selections of instruments) between 1976 and 1979, and map the Loudness Wars of the past few decades, as the rise of the CD and a competition for sounding louder and more kick-ass than all the music that came before conspired to annihilate dynamic range:
Finally, another cultural trend that shows up in the data is the steady decline of the Truck Driver's Gear Shift (i.e., the tendency of songs to shift their key up one or two semitones before the final chorus, for some extra heartstring-tugging oomph) from the 1950s to the present day; presumably because that shit got old. When the incidence of gear shifts is plotted by month, however, few will be surprised to find that December has 2-3 times as many as the rest of the year; after all, 'tis the season to be cheesy.
The percentage of loud tracks has increased from 10% in 1964 (by definition) to over 40% in recent years. So music has got louder. Well, isn't that in the spirit of Rock'n'Roll? Sadly, it isn't, because the increase in loudness has led to worse sound quality. Granted, it's louder, but boy is it flat!
2010/12/30
Following in the footsteps of OKCupid's data-mining blog, some people at Facebook have recently analysed a sample of status updates by word category, extracting correlations between word categories (as well as overall subject matter and positivity/negativity), time of day and probability of updates being liked/commented on. The analysis has shown, among other things:
- there are correlations between word categories and age; older people use more first-person plurals, positive emotions and references to religion and family, while young people tend to talk in the singular first-person (presumably adolescent alienation?), mention sadness and death, swear a lot and talk about sex, music and TV.
- People with more friends talk more about social processes and other people, and have higher total word counts; whereas, while talking about home, family and emotions are correlated with having fewer friends, the most strongly correlated categories are time and the past.
- Positive emotions are one of the most likely categories to be liked, but least likely to attract comments. Negative emotions, however, attract a lot of comments (presumably from the people posting empathetic "Don't Like" messages).
- The one thing less likeable than negative emotions is talk about sleeping.
- People who talk about metaphysical or religious subjects are most likely to be friends. And people who use prepositions a lot tend not to be friends with people who swear a lot or exhibit anger or negative emotions.
2010/9/10
The latest instalment of OKCupid's data-mining blog looks at the thorny question of race again; this time, analysing the text of users' profiles, correlated by self-identified racial group.
One part of the article mines keywords unique to racial groups from profiles and presents them as tag clouds, resulting in unsubtle stereotypes. It appears that white people here are not White People; white males are straight-up bros/bogans, into Tom Clancy, sweaty guitar rock, and petrol consumption as recreation, and the females are into spectator sports and a mess of wild-nature clichés, such as thunderstorms, horses and bonfires. (An Irish-American cast looms over both genders, with "Ireland" and plastic-Paddy brocore band Dropkick Murphys rating a mention.) Meanwhile, black people are religiously demonstrative (they're more than twice as likely to mention religion as white or Asian profiles), and Asian and Indian users mention interests in hard-headed professions such as mathematics, engineering and computers, and literature such as Freakonomics, Malcolm Gladwell and Calvin & Hobbes. That and the usual stereotypes.
Among the take-aways from this post: if you want to know if white dudes will like something, put "fucking" in the middle and see if it sounds badass. Hence "Van fucking Halen" and "The Big fucking Lebowski", but not "Alicia fucking Keys". (Of course, it breaks down if irony comes into it; if you're dealing not with bros but with hipsters mining the battlefront of the pop-cultural goldmine, they can get away with a lot of stuff. Take, for example, Fleetwood fucking Mac, or Hall and fucking Oates. This does has its limits, though; chances are, there isn't a hipster with big enough post-ironic cojones to make "Celine fucking Dion" sound right.)
Further down, OKCupid also ran a reading-level analysis algorithm over users' profiles, and correlated it with race and religion. The results were fairly close, though self-identified Indians and Asians had the best-written profiles, with "Latino", "black" and "white" profiles being in the bottom half. More interestingly, the analysis by religion shows a distinct inverse correlation between religiosity and writing level.
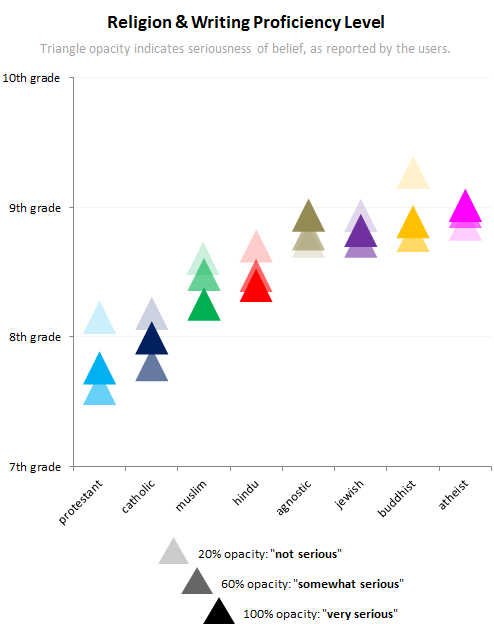
Note that for each of the faith-based belief systems I've listed, the people who are the least serious about them write at the highest level. On the other hand, the people who are most serious about not having faith (i.e. the "very serious" agnostics and atheists) score higher than any religious groups.
2010/8/11
The latest instalment of the OKCupid team's data-mining project looks at the correlations between the attractiveness of profile pictures attractiveness and the EXIF metadata contained in them. Among other things, it has found that:
- While a better camera may not make you a better photographer, it will make you look sexier (assuming you're being photographed with it, that is). Photos taken with Micro Four-Thirds cameras looked the best, followed by those taken with DSLRs, then compacts and finally camera phones, with Windows and Motorola phones taking the most minging profile pictures.
- Apple products do get you laid. or at least iPhone users have richer love lives than users of other smartphones.
- If you wish to take a flattering photo, open the aperture, getting a nice short depth of field (having a good camera, or at least not a cameraphone, helps here) and, for God's sake, don't use flash. (Unless perhaps you're going for that abject hipster porn aesthetic you see in American Apparel ads and Terry Richardson features in Vice.)
- The golden hour is not a myth; attractiveness of photos does spike immediately after sunrise and before sunset.
2010/6/16
Some good news from London: Transport For London, who run the city's public transport networks, have announced that they will be opening access to all their data by the end of June. The data will include station locations, bus routes and timetable information, and will be free from restrictions for commercial or noncommercial use.
The data will be hosted at the London DataStore, a site set up to give the public access to data from public-sector organisations serving London. A few sets are already up, as well as a beta API which returns the locations of Tube trains heading for a specific station. Which could probably be worked into a mobile app to tell you when to start walking to the station. If they had something like this giving the positions and estimated arrival times of buses (whose travel times are considerably more chaotic than those of trains, and which often run less frequently, especially at night), that would be even more useful. (Some approximation of this facility exists in the LED displays, which are installed at some bus stops and sometimes are operational; a XML feed and a mobile web app would probably be a more cost-effective way of getting this information into the hands of commuters.)
Another thing that would be useful would be an API for the Transport for London Journey Planner; being able to ping a URL, passing an some postcodes or station names, a departure/arrival time and some other constraints, and get back, at your option, a maximum journey time or a list of suitable journeys, in XML or JSON format, would be useful in a lot of applications, from device- or application-specific front ends (i.e., a "take me home from here" mobile app) to ways of calculating the "inconvenience distance" between two points by counting travel time and changes (i.e.,in terms of travel convenience, Stratford is closer to Notting Hill than Stoke Newington, despite being further in geographical terms, as it's a straight trip on the Central Line).
2010/3/5
The social network site Facebook is supported by advertising. Being a social network site, it has the advantage of being able to serve (anonymously) targeted ads to its users, who volunteer demographic information about themselves in using the site; advertisers can target ads to users whose profiles or recent activities match certain criteria. Unfortunately, when handled clumsily, the effect can be disconcerting or creepy:
One campaign that flooded the site in recent weeks, before Facebook cracked down on it, tries to take advantage of consumer interest in Apple’s iPad. “Are you a fan of Eddie Izzard? We need 100 music and movie lovers to test and KEEP the new Apple iPad,” one version of the ad says. Louis Allred Jr., 29, a Facebook user in Los Angeles who saw the ad, said he figured it was shown to him because he or a friend had expressed enthusiasm for Mr. Izzard, a British comedian, on their profiles.Off-key and/or sleazy ads on Facebook are nothing new, of course; ads juxtaposing pictures of hot chicks with unrelated, often dubious-looking, offers, for example, have been on the service for years, and presumably have snared a number of not particularly discerning individuals. But now Facebook are allowing advertisers to effectively write templates to be filled in with users' details ("SPECIAL OFFER FOR $gender AGED $(age-1)-$(age+1) WHO LIKE $interest"). Which sounds like a way to game unmerited trust out of punters, but, more often than not, falls into an uncanny valley, falling short of being convincing and coming off as unsettling, or worse:
Women who change their status to “engaged” on Facebook to share the news with their friends, for example, report seeing a flood of advertisements for services and products like wedding photographers, skin treatments and weight-loss regimens.And the knowledge that ads are targeted by some data-mining algorithm can, in itself, add a dimension of unease to what might well be coincidences:
Jess Walker, 22, from central Florida, was recently presented an ad for Plan B, the morning-after pill. “What do I have on my Facebook page that would lead them to believe I would need that?” she asked, adding that she did not want her sexual behavior called into question.
2010/2/9
Pete Warden, a programmer and amateur researcher, has analysed the data from public Facebook profiles, including the relative locations of pairs of friends and people's names and fan pages, and used this to divide the US into seven relatively self-contained clusters, which he terms "Stayathomia" (i.e., the northeast to midwest), "Dixie" (the old South), "Greater Texas" (encompassing Oklahoma and Arkansas), "Mormonia" (no prizes for guessing where that is), the "Nomadic West" (places like Idaho, Oregon and Arizona, where people's connections span wide areas), Socalistan (i.e., most of California and parts of Nevada) and Pacifica (essentially Seattle). The clusters were derived from performing cluster analysis on the social graph, and not imposed on the data a priori.
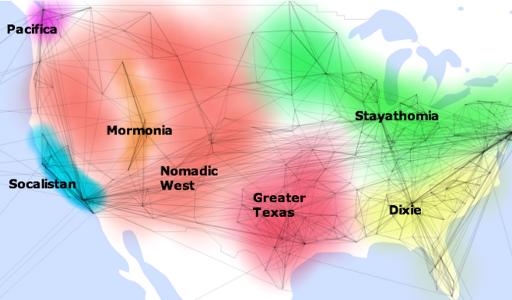
Warden posts various findings he gained from crunching the data on these clusters:
Probably the least surprising of the groupings, the Old South is known for its strong and shared culture, and the pattern of ties I see backs that up. Like Stayathomia, Dixie towns tend to have links mostly to other nearby cities rather than spanning the country. Atlanta is definitely the hub of the network, showing up in the top 5 list of almost every town in the region. Southern Florida is an exception to the cluster, with a lot of connections to the East Coast, presumably sun-seeking refugees. God is almost always in the top spot on the fan pages, and for some reason Ashley shows up as a popular name here, but almost nowhere else in the country.
(Greater Texas:)God shows up, but always comes in below the Dallas Cowboys for Texas proper, and other local sports teams outside the state. I've noticed a few interesting name hotspots, like Alexandria, LA boasting Ahmed and Mohamed as #2 and #3 on their top 10 names, and Laredo with Juan, Jose, Carlos and Luis as its four most popular.
(Mormonia:) It won't be any surprise to see that LDS-related pages like Thomas S. Monson, Gordon B. Hinckley and The Book of Mormon are at the top of the charts. I didn't expect to see Twilight showing up quite so much though, I have no idea what to make of that!Mormons like their vampires sparkly and pro-abstinence; who would have guessed?
(Socalistan:) Keeping up with the stereotypes, God hardly makes an appearance on the fan pages, but sports aren't that popular either. Michael Jackson is a particular favorite, and San Francisco puts Barack Obama in the top spot.Warden also has this tool for browsing aggregate profiles of countries based on their residents' public Facebook profiles.
2008/1/26
A chap named Virgil Griffith has correlated the most popular books at every college in the US (as fetched from Facebook) with that school's average test score to find a correlation between intelligence and favourite books. According to Griffith's study, the book most correlated with high scores is Vladimir Nabokov's Lolita, and that with low scores is the Holy Bible (not to be confused with the Bible, which is around the middle, just below Harry Potter); other books correlated with high scores are Ayn Rand's Atlas Shrugged, Kurt Vonnegut's Cat's Cradle, and Freakonomics, and books dumber than "I Dont Read" include various erotica and hip-hop/ghetto fiction, The Purpose Driven Life and Fahrenheit 451. Slightly smarter than not reading are the likes of Fight Club, Dan Brown and John Grisham, along with Shakespeare's Hamlet; sci-fi, fantasy and geek/fan-interest books like The Lord of the Rings, Dune and, umm, Eragon rate more highly. (Mind you, this is correlated to test scores, not cultural well-roundedness.)
It would be interesting to see one of these correlating a measure of intelligence (such as test scores) with other factors, such as favourite music (I imagine things that a lot of geeks listen to, like metal, industrial and prog rock would come out on top, and rap-metal/nu-metal and R&B would come out fairly low), movies, or even which Facebook groups/applications one has installed.
(via Boing Boing) ¶ 3
2006/12/4
UnSuggester is a book recommendation engine in reverse; enter a book you liked, and it'll give you a list of books you probably won't like. Apparently, fans of William Gibson's Neuromancer and Michael Moore's Stupid White Men would least want to read books on theology, the opposites of Marx & Engels' Communist Manifesto look like erotica novels, Bulgakov's The Master and Margarita is the least like an array of romance novels, Star Wars novelisations and theological texts, and the opposites of Design Patterns are mostly chick-lit, whereas The Little Prince finds itself to be the antithesis of thrillers and scifi novels. Meanwhile, people who read Illuminatus! are unlikely to read Freakonomics, and the opposite of The Da Vinci Code, with its simplistic structure and grand revelations, appears to be, naturally enough, French postmodernist philosophy.
2005/7/29
A researcher at the veritable MIT Media Lab is mining volunteers' mobile phone location and call data, and using it to determine all sorts of things, from simple things such as how long people work and how much they procrastinate to which people are friends and which ones are merely coworkers. Not only that, but the data can predict people's behaviour:
Given enough data, Eagle's algorithms were able to predict what people -- especially professors and Media Lab employees -- would do next and be right up to 85 percent of the time.
Eagle used Bluetooth-enabled Nokia 6600 smartphones running custom programs that logged cell-tower information to record the phones' locations. Every five minutes, the phones also scanned the immediate vicinity for other participating phones. Using data gleaned from cell-phone towers and calling information, the system is able to predict, for example, whether someone will go out for the evening based on the volume of calls they made to friends.
Eagle was also able to see that the Red Sox's improbable breaking of the World Series curse shook even the world of MIT engineers. "I actually saw deviation patterns when the Red Sox won," Eagle said. "Everyone went deviant."The information was recorded by special custom programs running on the phone; the same information is gathered by the mobile network operators, though is not available to the general public. However, it is available to law-enforcement agencies, and is probably being used right now for assembling automated dossiers on entire populations.
2004/2/12
A data-mining technology developed for hunting down criminals, and used to identify backpacker killer Ivan Milat, is now being adapted to identifying consumer preferences by analysing their purchases and media choices:
"We know the people who drink a certain type of coffee will also eat specific types of chocolate bars and eat at particular food chains," said Torque's managing partner, Oliver Rees. "It's not only interesting for marketing those products to specific people but also for how store layouts are designed and how brand alliances should or could develop."